hide forever | hide once
hide forever | hide once
Joint Recovery of Dense Correspondence and
|
||
|
|
||
|
|
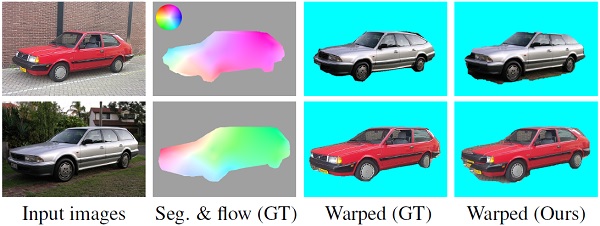
Abstract -- We propose a new technique to jointly recover cosegmentation and dense per-pixel correspondence in two images. Our method parameterizes the correspondence field using piecewise similarity transformations and recovers a mapping between the estimated common “foreground” regions in the two images allowing them to be precisely aligned. Our formulation is based on a hierarchical Markov random field model with segmentation and transformation labels. The hierarchical structure uses nested image regions to constrain inference across multiple scales. Unlike prior hierarchical methods which assume that the structure is given, our proposed iterative technique dynamically recovers the structure along with the labeling. This joint inference is performed in an energy minimization framework using iterated graph cuts. We evaluate our method on a new dataset of 400 image pairs with manually obtained ground truth, where it outperforms state-of-the-art methods designed specifically for either cosegmentation or correspondence estimation. |
|
| We released our new dataset and evaluation kit!! |
||
  |
|
|
Supplementary Video
|
||
|
|
||
Score Correction of Benchmark |
||
| We identified a bug in our initial evaluation code. Because of this, the segmentation accuracy numbers in Table 1 were incorrect. The corrected numbers are shown in the following table (PDF). The changes of the scores are small and they do not change the relative performances of the methods, compared to the originally reported results. If you want to use our dataset and evaluation results in your work, please cite the corrected vesion. This issue has been fixed in the latest evaluation tool and score sheets in the above links. | ||
|
 |
||